
10x AI Token Efficiency: Visual Tokenizers and Text Compression
The surprising power of lossy compression: How AI decodes fuzzy visual patterns.

“A picture is worth a thousand words.” - Napoléon Bonaparte
Take a look at the image below. You can probably read it, even if it’s a bit blurry. That simple act of recognition—effortlessly decoding a fuzzy, compressed picture of words—is the key to a profound shift in artificial intelligence.

I recently saw an announcement for an open-source model called DeepSeek-OCR (paper). While interesting on its own, it was a comment by AI expert Andrej Karpathy that exposed the revolutionary idea behind it. As someone who isn’t a model architecture expert, I tried to understand the intuition behind the excitement. It seems the real breakthrough isn’t just about reading text from an image; it’s about using images to solve AI’s biggest bottleneck: efficiently compressing text.
The Real Problem: Tokenization is Inefficient Compression
Every time an AI model “reads,” it first performs tokenization. Think of it as a compression algorithm. It takes text and converts it into a compact sequence of numbers (tokens) using a fixed dictionary. But as a compression tool, it’s surprisingly inefficient.
The core limitation is that this process is rigid and discrete. A token must be a perfect match to a dictionary entry. There is no concept of a “blurred” or “fuzzy” token that represents the general shape of a word. There is no obvious way to blur text in its tokenized form.
This rigidity leads to two major inefficiencies:
It’s Brittle: A single typo or a rare word forces the tokenizer to break it down into multiple, less meaningful pieces. It can’t just “squint” and get the gist.
It Imposes a “Token Tax”: Its dictionaries are often English-centric. For other languages, words are frequently broken into many more tokens, making the compression far less effective and driving up costs for non-English users.
Traditional tokenization is a lossless, but highly inefficient, compression algorithm. To achieve a true leap in performance, we need a better approach.
The Breakthrough: Lossy Compression by Seeing
This is where the new paradigm comes in: treat text as an image.
The act of rendering a large amount of text into a small, fixed-size image is itself a powerful form of lossy compression. You lose pixel-perfect sharpness, but you preserve the essential patterns. It’s just like the blurry image at the start of this article. You can read it because your brain is a master of pattern recognition, filling in the gaps from the “compressed” visual data.
An AI model can be trained to do the same. Instead of a dictionary of words, it learns a vocabulary of visual patterns. Each “image token” (a small patch of the picture) can now represent the visual information of many words.
This method is inherently more robust. It doesn’t care about typos, different languages, or stylized fonts. It only cares about the shapes. It’s a compression algorithm that understands the “fuzziness” of information.
The Result: A 10x Leap in Compression Efficiency
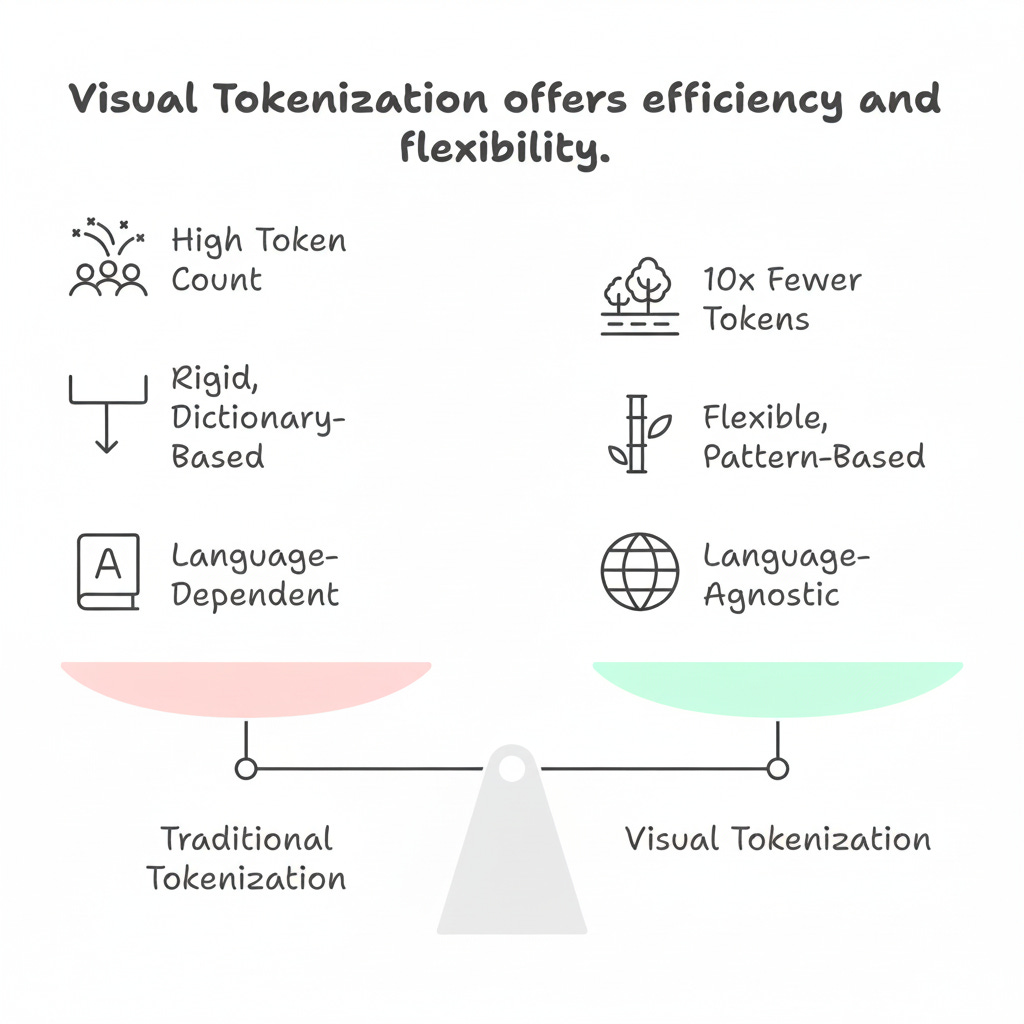
The difference is staggering. As Karpathy noted, a 1,000-word article that might require between 750-1,500 text tokens (depending on tokenizer and language) could be compressed into just 100 visual tokens. This is an up to 10x improvement in compression efficiency, per DeepSeek benchmarks, and it changes everything:
It’s Dramatically Faster and Cheaper: Fewer tokens mean less computation. Processing massive documents becomes exponentially more cost-effective.
It’s Language-Agnostic: The “token tax” is eliminated. The model is compressing visual shapes, not language-specific words. This makes AI truly equitable across all languages.
It Unlocks Holistic Understanding: The AI can now understand layout, tables, and charts natively. It’s not just reading a string of words; it’s interpreting a document.
From my perspective as an engineer, this shift from a rigid, dictionary-based compression method to a flexible, visual one isn’t just a small improvement—it feels like a fundamental upgrade to the engine of our AI models. While still an emerging and experimental field, with models like DeepSeek-OCR currently focused on specific applications, the potential for broader LLM integration is immense. It suggests the most efficient way to process text at scale isn’t to read it more carefully, but to step back and see the bigger picture.
Please comment, and share if you feel compelled to do so.
I appreciate you reading. Thanks to the new subscribers! ✌
For those who are more active on other platforms, you can also find me on LinkedIn or X.